奈良県のある住宅会社の営業部長は、会議室の机に座ってため息をつきました。提案書 1 本に、また 4 時間かかったのです。過去 3 年分の類似案件は社内 NAS のどこかに眠っているはず。けれど 「どこかにある」を「いま見つける」に変える方法がありません。
「 に聞けばいい」と言う若手もいます。しかし ChatGPT は、自社の過去案件を知りません。架空の事例を もっともらしく作って返してくる。検証に余計な時間がかかるだけでした。
3 週間後。同じ営業部長は、提案書の初稿を 12 分で仕上げていました。質問するだけで、過去 287 件の類似案件から最適なものを引用しながら、AI が下書きを書いてくれるようになったからです。
その正体が、本記事のテーマ (-Augmented Generation) です。
ChatGPT が抱える「致命的な弱点」
生成 AI を業務に入れたい、と考える経営者は多くなりました。一方で、現場での導入はあまり進んでいません。理由はシンプルです。
生成 AI は「知らない」と言えないからです。
知らない情報を聞かれても、それらしい答えを作って返してきます。これを「ハルシネーション(幻覚)」と呼びます。社内の固有名詞・実績数値・過去の議論経緯 — そういった学習データに含まれていない情報こそ、業務で本当に必要な情報なのに、AI はそこが一番苦手なのです。
| 質問内容 | ChatGPT 単体の答え | 業務で必要な答え |
|---|---|---|
| 「2024 年の関西エリアの注文住宅平均坪単価は?」 | 一般論を回答(学習データ次第) | 自社案件の実数値で答えてほしい |
| 「過去にあった『地下室付き』案件は?」 | 「私には情報がありません」 or 創作 | 3 件あった事例を引用付きで |
| 「先月の経営会議で何が決まった?」 | 完全に答えられない | 議事録から該当箇所を抜粋 |
この穴を埋めるのが RAG です。
RAG は「資料を見ながら答える」だけ
RAG の仕組みは、本質的にはとてもシンプルです。AI に「自分で答えるな、この資料を読んで答えろ」と命じる、それだけ。
技術的には 4 段階に分かれます。
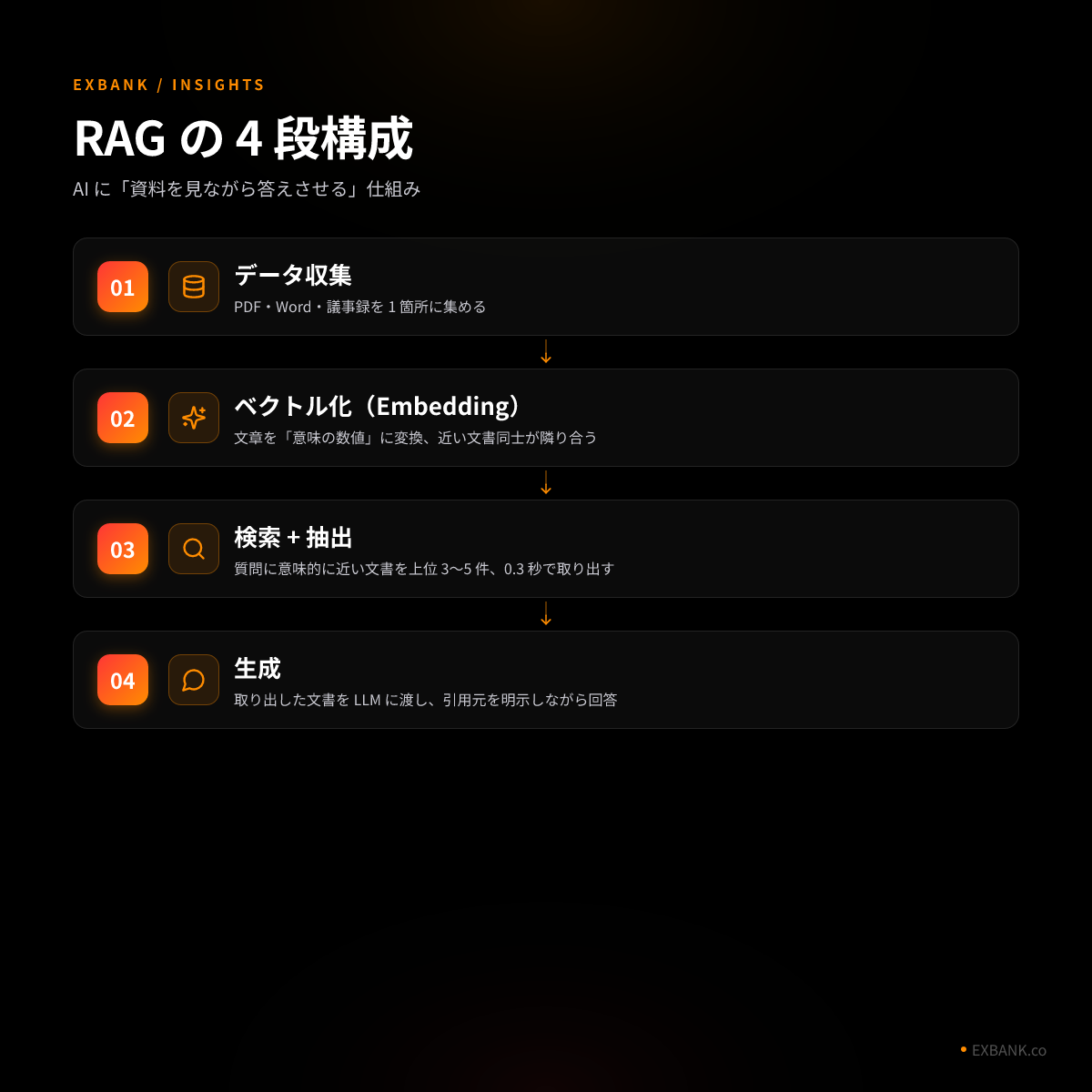
01. データを集めて「箱」に入れる
PDF・Word・スプレッドシート・Slack のログ・ の議事録 — 答えに使いたい情報を全部 1 箇所に集めます。形式は問いません。
02. 文章を「数字の指紋」に変換する
ここが少しだけ技術寄りです。(埋め込み)と呼ばれる処理で、文章を 1,536 次元のベクトルに変換します。難しく聞こえますが、「意味の似ている文章は数値的にも近くなる」状態を作るだけです。
たとえば「広告 を改善する」と「リスティングのコスト効率を上げる」は、表記が違っても意味が近い。Embedding 後はベクトル空間で隣り合います。これで意味検索が可能になるわけです。
03. 質問が来たら「近い文書」を引っ張る
ユーザーが質問すると、その質問文も同じく Embedding されます。ベクトル DB から、意味的に近い文書を上位 3〜5 件取り出します。0.3 秒の世界です。
04. AI に「これを読んで答えて」と指示する
取り出した 3〜5 文書を、プロンプトに添えて LLM に投げます。「以下の資料に基づいて回答してください。資料に無いことは『情報なし』と答えてください」と縛ります。これだけで、ハルシネーションは劇的に減ります。
💡 KEY TAKEAWAYS
RAG は新しい技術ではなく、「LLM に毎回カンペを渡す仕組み」です。(モデル再学習)と違い、データ更新が即時反映され、運用コストが 1/30 に下がります。300 ファイル程度から効果が出始めます。
マーケで効く 5 つの応用 — 全部、現場で見たケースです
「RAG は便利そうだけど、うちの業務で使えるか分からない」 — そう感じる方のために、当方が実際に支援した中で特に費用対効果が高かった 5 領域を紹介します。
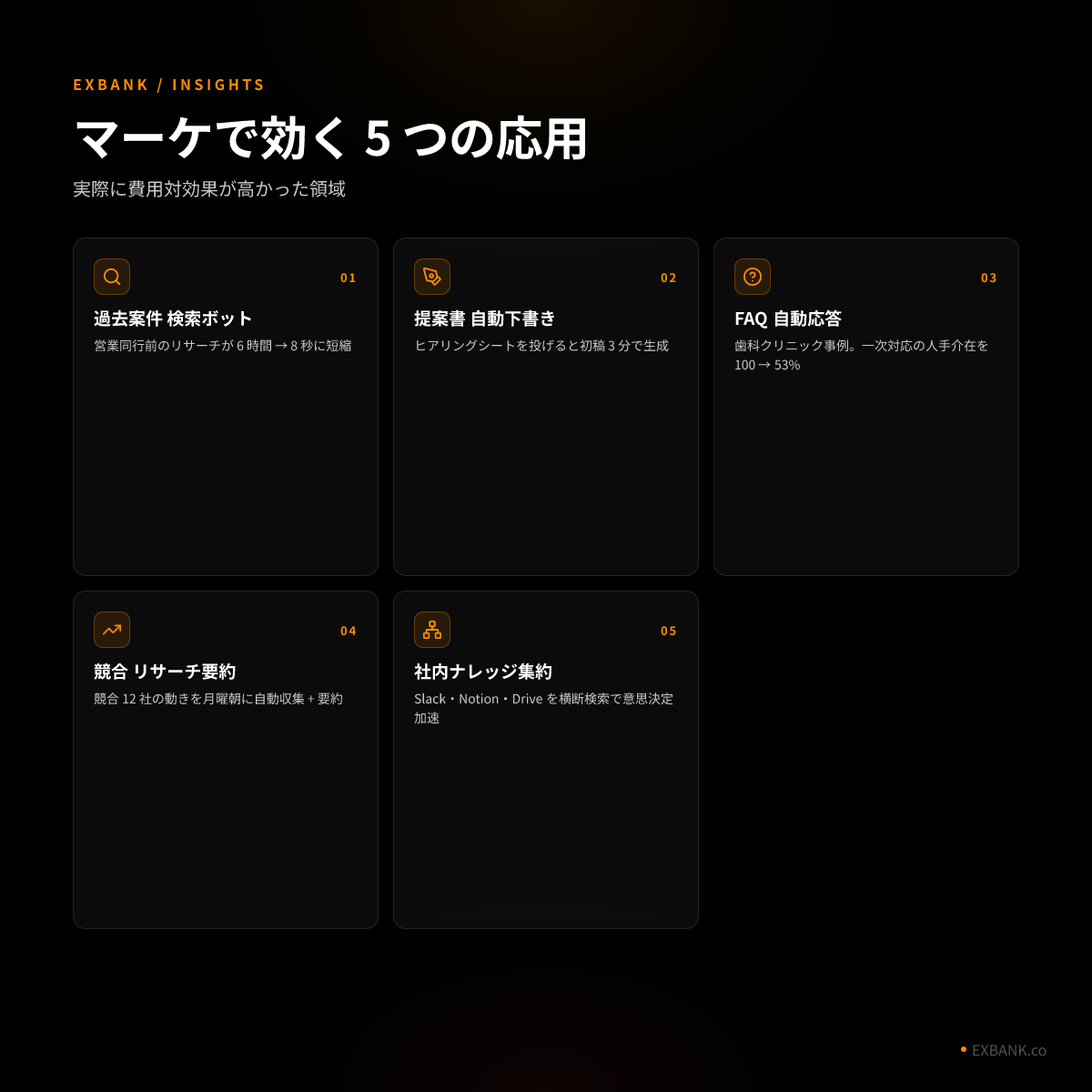
01. 過去案件 検索ボット — 営業同行前のリサーチが 1/5 に
冒頭の住宅会社のケースです。営業部長は商談前に必ず「似た案件あった?」を 5 名のメンバーに Slack で聞いていました。返事が返ってくるのは平均 6 時間後。
RAG 導入後、Slack のスラッシュコマンド /case で過去 287 件から条件マッチを 8 秒で抽出できるようになりました。営業部 8 名 × 平均 4 商談/週 × 旧 6 時間 = 週 192 時間の損失が消えた計算です。
02. 提案書 自動下書き — 4 時間 → 12 分
ヒアリングシート(A4 で 2-3 枚)を投げると、過去の類似提案を参考に初稿が 3 分で生成されます。
ここで重要なのは、完成版ではなく初稿だという割り切り。AI は 70% の品質まで持っていきます。残り 30% は人間がブラッシュアップ。これを「叩き台ファースト」運用と呼んでいます。
注意点: 100% AI 任せにすると、過去案件の数値をそのまま流用してハルシネーションを起こします。「金額は必ず人間が更新する」というルールを徹底してください。
03. FAQ 自動応答 — 一次対応の 47% を無人化
歯科クリニックチェーンの導入事例です。Web フォームの問い合わせを RAG で分類 → 過去回答から最も近いものを引用付きで提案 → 担当者が承認して送信、というフローです。
| 項目 | Before | After(3 ヶ月後) |
|---|---|---|
| 一次対応の人手介在率 | 100% | 53% |
| 平均回答時間 | 4 時間 12 分 | 31 分 |
| 担当者の負荷感(1-5) | 4.6 | 2.1 |
AI が「この問い合わせには過去のこの回答が近い」と提案してくれるだけで、ゼロから書く負担が消えました。
04. 競合 リサーチ要約 — 週次会議の準備が 30 分に
競合 12 社のプレスリリース・公式ブログ・主要レビューサイトを毎週月曜の朝に自動収集 → 「自社視点で見た重要ポイント TOP 5」を要約して Slack に流す、という運用です。
マーケ部長は月曜 9 時の会議にコーヒー片手で挑めるようになりました。準備が消えた、ではなく、準備が意思決定に変わったのです。
05. 社内ナレッジ集約 — 「あの件どこで決まった?」が消える
これは地味ですが効きます。Slack ・Notion ・ ・Email の議事録すべてを横断検索可能にする運用です。
「あの案件、価格交渉どこまで OK だっけ?」「去年の制作会社、結局なんで切ったんだっけ?」 — こうした 思い出せない情報は、企業の意思決定速度を確実に削っています。RAG はこの摩擦を消します。
導入で必ずハマる 4 つの落とし穴
ここから先は、実際に転んだ人だけが知っている話です。当方が見てきた失敗パターンを、痛みとセットで共有します。
落とし穴 1: チャンク分割を「単純な 500 字区切り」にする
最も多い失敗です。長文を機械的に 500 字で区切ると、重要な文の途中でぶつ切りになります。「 を実装する場合、必須要件は 」 — ここで切れる。続きが取れない。AI は意味不明な答えを返す。
正解は 見出し単位 + 段落単位での分割。さらに前後 100 字ほどのオーバーラップを持たせます。これだけで検索精度が 1.4-1.8 倍になります。
落とし穴 2: 似たような文書だけが取れてくる
「Meta 広告 CPA 改善」で検索したら、5 件全部 CPA 改善のテンプレ記事だけ。違う角度の知見が取れない。
解決策は 2 つあります。
- Re-ranking(再順位付け): 1 段目で 20 件取り、2 段目で多様性を保ちつつ 5 件選ぶ
- クエリ拡張: 元の質問を 3 つの言い換えに分散させてから検索
API を入れるだけで実装でき、月 3,000 円程度です。
落とし穴 3: ハルシネーションが「減ったけど消えない」
文書を渡しても、AI は「資料に無いことを足してしまう」癖が抜けません。3 つのプロンプト指示で激減します。
- 「資料に明記がない場合は『情報なし』と答えてください」
- 「回答の根拠となる文を、引用元と共に sentence-level で示してください」
- 「資料の解釈に揺れがある場合は、その揺れを明示してください」
特に 2 番目が効きます。引用元を強制すると、AI は嘘をつきにくくなります。
落とし穴 4: 評価指標を作っていない
「動いている気はするけど、品質はどうなのか」 — この質問に答えられない RAG プロジェクトは、半年後に静かに死にます。
最初に必ずやるべきは、テストセットの作成です。
- 質問 100 件
- 各質問に「期待する答え」と「期待する引用元」を付ける
- 週次で正答率を測定する
/ Phoenix / Ragas のような専用ツールもありますが、最初は Google Spreadsheet で十分です。「質問 / 期待答 / 実際答 / 評価(◎ ◯ △ ✕)」の 4 列で始めてください。
Tips: 評価指標、最初の 1 ヶ月でやること
- 業務担当者 3 名に「あなたが日常的に困っている質問を 30 個ください」とお願いする
- それぞれに「理想の答え」を書いてもらう
- RAG に同じ質問を投げ、答えを並べて評価
- ◎ が 60% を超えるまで、チャンク分割・プロンプト・Re-ranking を回す
- ◎ 80% で本番展開、◎ 95% で「卒業」レベル
現実的なアーキテクチャ — 3 つのスケール
「結局、何を使えばいいの?」に答えます。当方が 30 件超の RAG 案件で見てきた実用ラインです。
| 規模 | LLM | Embedding | ベクトル DB | 月額コスト | 実装期間 |
|---|---|---|---|---|---|
| 小(PoC) | Haiku / GPT-4o-mini | text-embedding-3-small | (ローカル) | 5,000〜15,000 円 | 2-3 週間 |
| 中(部署) | Claude Sonnet / GPT-4o | text-embedding-3-large | / | 5〜15 万円 | 2-3 ヶ月 |
| 大(全社) | Claude Opus + Sonnet 併用 | text-embedding-3-large | / Vertex AI | 30〜100 万円 | 4-6 ヶ月 |
迷ったら、小から始める — これに尽きます。「全社 RAG」を 6 ヶ月かけて作って、誰も使わない、という失敗を当方は 3 回見てきました。逆に部署 1 つで爆発的に使われた事例は、ほぼすべて PoC からの段階的拡大でした。
RAG が効かない 3 つの場面
正直にお伝えします。RAG は万能ではありません。むしろ向かない領域を最初に把握しておく方が、投資判断が楽になります。
- 数値計算・データ集計: / BI ツールが圧勝です。「先月の売上 TOP 10」のような構造化クエリは RAG にやらせる意味がありません
- リアルタイム性必須の業務: 社内 KPI モニタリング、チャットの即時返信は RAG に向きません。Embedding に時間がかかるからです
- 創造性が主目的: 既存資料に縛られると発想が広がりません。ブレストや企画案出しは素の LLM の方が良いケースが多いです
次の 3 アクション
ここまで読んでくださったあなたに、明日からやれる順で 3 つご提案します。
- 30 分で触ってみる: ChatGPT Projects / Claude Projects に社内資料を 5 ファイル投げて質問する。これは事実上の簡易 RAG で、感覚が一気に掴めます
- PoC を 1 業務に絞る: 「過去案件検索」など効果測定しやすい単一業務から。3 業務同時着手は失敗します
- 3 ヶ月後の評価指標を最初の 1 週間で決める: 動かす前に、何をどう測るかを決める。これだけで成功率が体感 3 倍違います
ここまで読んで「ウチは AI で動ける体質か?」と気になった方は、まず 細マッチョ企業診断 で 3 分セルフチェックすることをおすすめします。5 軸スコアで、AI 投資が効く土壌が貴社にあるかを即時に可視化できます。
EXBANK では、RAG の PoC 設計から本番運用、社内チームへの伴走まで一気通貫で支援しています。「自社業務にハマるか分からない」段階の壁打ちこそ、当方が最も価値を出せる場面です。
30 分の無料相談で、貴社の状況と業務フローから「RAG が効きそうな筋」と「最初に止めるべき罠」をその場でご返答します。お気軽にご相談ください。